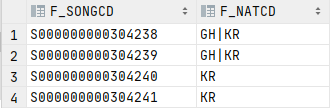
해당 데이터 중 F_NATCD 열의 데이터를 | 로 구분하여 행으로 표현 할 것이다.
1. connected by level
오라클에서의 for문이라고 보면된다. 조건을 넘지않는한 계속 반복하여 쿼리를 수행한다.
select level from dual connect by level<10;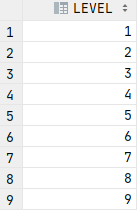
2. REGEXP_REPLACE 정규식
LENGTH(REGEXP_REPLACE(f_natcd,'[^|]+',''))+1 정규식과 LENGTH를 활용하여 구분자 개수만큼 반복실행할 수 있도록 해준다.
ex) 데이터가 aaa | bbb | ccc 라면 REGEXP_REPLACE(f_natcd,'[^|]+','') 의 반환값은 | | 이 되고 LENGTH 값은 2가 나오게 된다.
3. REGEXP_SUBSTR 정규식
2번의 REPLACE와 비슷한 정규식이다
regexp_substr(f_natcd, '[^|]+', 1, level) 을 사용하게되면 구분자 | 로 분리한 후 level 값 위치에 있는 데이터를 반환해준다.
1,2,3 번을 활용하여 데이터를 행으로 표현해보자
select F_SONGCD, regexp_substr(f_natcd, '[^|]+', 1, level) as f_natcd, level
from T_ALBUM_LOG_ORI
connect by level <= LENGTH(REGEXP_REPLACE(f_natcd,'[^|]+',''))+1
위 쿼리를 실행하게되면
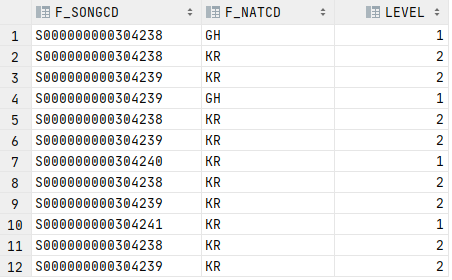
이런식으로 뭔가 이상하게 나오게될것이다.
분명 총 6개가 나와야되는데 반복이 이상하게 된 느낌일것이다.
표현해야될 데이터 기준으로 LENGTH(REGEXP_REPLACE(f_natcd,'[^|]+',''))를 하면 1이 나온다.
중복된 행을 제외시키기위해
select F_SONGCD,f_natcd FROM (
select F_SONGCD, regexp_substr(f_natcd, '[^|]+', 1, level) as f_natcd, level
from T_ALBUM
connect by level <= LENGTH(REGEXP_REPLACE(f_natcd,'[^|]+',''))+1
group by F_SONGCD, f_natcd, LEVEL);그룹핑을해주었는데
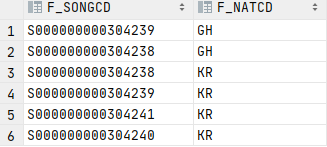
원하는결과값이 나오기는 하였으나 왜 중복된 행이 나오는지는 찾지못하였다.
추후에 찾게된다면 다시 수정을해야될부분인듯하다.
(수정)
conntect by level 에서 중복되지않도록 하는 방법
connect by f_seq=prior f_seq
and prior sys_guid() is not null
and level <= LENGTH(REGEXP_REPLACE(f_natcd,'[^|]+',''))+1위 처럼 특정 key를 prior 연산자를 사용하여 상위 행이라고 표시해줘야된다.
connect by 절은 계층구조 쿼리이기때문에 해당 쿼리가 상위 or 하위 계층으로 전개할지 정해줘야된다. 수정 전에는 prior 연산자가 없어서 중복이 나왔으며 n*n 을 한것처럼 어마어마한 쓰레기 데이터가 결과값으로 나오게되었다.
connect by 절과 prior 은 꼭 함께 쓰도록하자
요약정리
1.connect by level은 오라클에서 사용할 수 있는 for문같은 것이다.
2.구분자로 나뉘어져있는 데이터를 행으로 표현하고 싶을때는 regexp의 정규식함수와 connect by level 함수를 적절하게 사용하면 가능하다.
3. regexp 의 정규식 함수는 오라클 10 버전 이후부터 사용가능하니 그전에는 substr 로 일일이 잘라야된다
'DB > Oracle' 카테고리의 다른 글
| pivot (오라클11g) (0) | 2025.03.14 |
|---|---|
| 오라클 bulk insert 속도개선 (0) | 2024.10.17 |
| drop 테이블 복구 (0) | 2024.08.07 |
| 오라클 DB링크 (0) | 2024.07.05 |
| 테이블 LOCK (1) | 2024.04.16 |
